Blog Posts

In today's data-driven world, businesses and individuals constantly deal with documents containing valuable structured information from invoices, receipts, reports, and financial statements. Manually extracting this data is time-consuming, error-prone, and simply not scalable. That's why we've developed a cutting-edge solution that leverages Google's Gemini 2.5 Pro and FastAPI to automate this process with remarkable accuracy.
 Areeba
Areeba

In today's digital world, automating document processing is crucial for businesses. One of the most common yet challenging tasks is extracting structured data from invoices. In this post, we'll break down a powerful Invoice OCR API that uses Google's Gemini 2.5 Pro to intelligently parse invoice images and extract both header information and line items.
Areeba



Optical Character Recognition (OCR) is a powerful tool for extracting text from images, and Rust provides excellent libraries to build high-performance OCR applications. In this tutorial, we'll create a Rust-based OCR API using Tesseract OCR (Leptess) and Actix-Web to process uploaded images and return extracted text.

If you need to extract individual pages from a PDF and convert them into high-resolution images, AI Viewz’s PDF to Image Converter is the perfect tool. This online service allows you to split a PDF into multiple images and download them as a convenient ZIP file. Follow this simple guide to get started.
 Usama
Usama


In this Guide You will learn how to combine pdf files in bulk using AI Viewz pdf merger as you know handling multiple PDF files can feel overwhelming. Whether you’re a professional juggling reports, a student organizing research, or a business owner consolidating invoices, the need for efficient document management is critical. Our online service offers a game-changing solution, allowing you to merge your bulk PDF files into a single, streamlined file.
Usama

If you're a Python developer who loves FastAPI for its speed and simplicity but wants to explore a Rust alternative, Actix-Web is the perfect choice. Actix-Web is a powerful, performant, and ergonomic web framework for Rust that rivals FastAPI in speed while offering Rust's safety guarantees.

Optical Character Recognition (OCR) is a crucial tool for extracting text from images, PDFs, and scanned documents. While Pytesseract is the most popular Python wrapper for Tesseract OCR, it suffers from performance bottlenecks due to its Python-based implementation.
 Naila
Naila
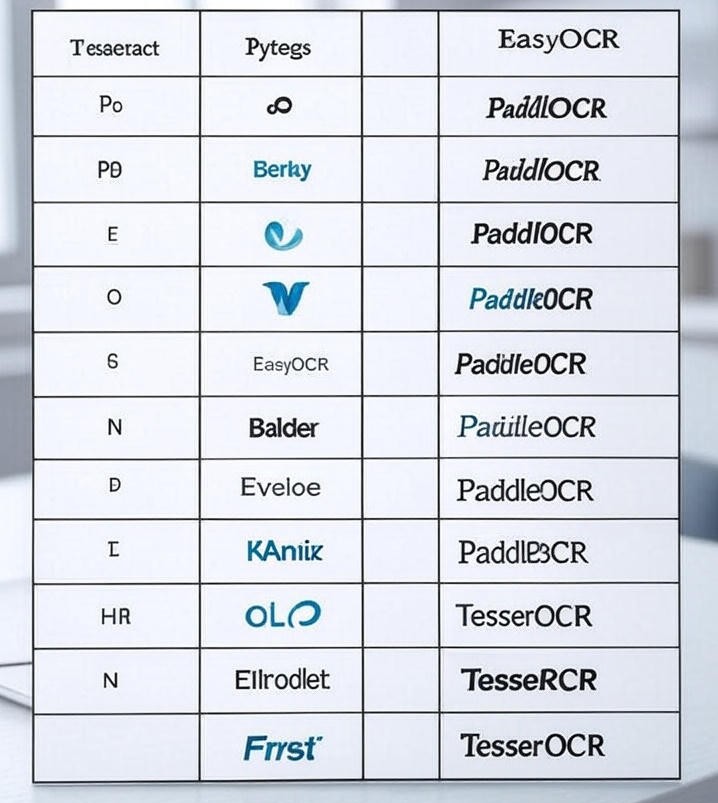
Optical Character Recognition (OCR) has revolutionized how machines interpret text from images. With several powerful OCR engines available, choosing the right one depends on factors like accuracy, speed, language support, and hardware requirements. In this blog post, we’ll dive deep into Tesseract OCR, Pytesseract, EasyOCR, PaddleOCR, and TesserOCR, comparing their performance, limitations, and best use cases.
Naila

Optical Character Recognition (OCR) is a powerful tool that converts images of text into machine-readable text. Among the most popular OCR engines is Tesseract OCR, an open-source solution developed by Google. Whether you're working on document processing, data extraction, or automation, installing the right version of Tesseract is crucial. In this guide, we’ll walk you through the installation process for different versions of Tesseract OCR, including stable and developer releases, as well as language packs.
 Rogue
Rogue