Understanding Vision Transformers: The Next Frontier in Computer Vision
Vision Transformers are changing the game of computer vision with the introduction of a new model which does not use convolutional layers instead it uses self-attention based architecture.
What Are Vision Transformers?
The vision Transporters are deep learning neural networks based on transformers used in natural language processing specifically developed to process images sequentially in a grid-like grid of blocks.
Vision Transformers are a kind of model that breaks an image into fixed-size patches with transformer encoders to comprehend the visual context..
Why Vision Transformers Matter in Modern AI
Vision Transformers are important as they provide the alternative to convolutional neural networks (CNNs) via adopting the practice of global self-attention to model long-range dependencies of image data.
Vision Transformers perform particularly well on image classification, object detection, and image segmentation tasks, particularly when used on large scale dataset such as ImageNet.
How Vision Transformers Work
Vision Transformers encode images the same way as words in a sentence, making them also processable with the same attention-based methods that transformed NLP.
Position encodings- Vision Transformers capture the spatial information of patches, and learn the image features with multiple layers of self-attention and feed-forward networks.
Key Components of Vision Transformers
Vision Transformers are built on major modules such as patch embedding, positional encoding, multi-head self-attention and classification heads.
Hierarchy exists in some variants of Vision Transformers and allows learning low-level features in the first layers and high-level semantics in later ones.
Advantages of Vision Transformers Over CNNs
When given sufficient amounts of data, Vison Transformers achieve substantial better generalization, transfer learning, and scalability than regular CNNs in a number of tasks.
Vision Transformers escape the inductive bias of CNNs and learn the association between image patches more broadly, and this makes the model useful in multiple image recognition tasks.
Challenges of Using Vision Transformers
In contrast to CNNs, Vision Transformers need much bigger training datasets and computations budget and are more appropriate to large-scale AI initiatives.
Sometimes, Vision Transformers are observed to overfit to smaller training sets, and techniques such as data augmentation, pretraining or distillation can be used to ensure good generalization.
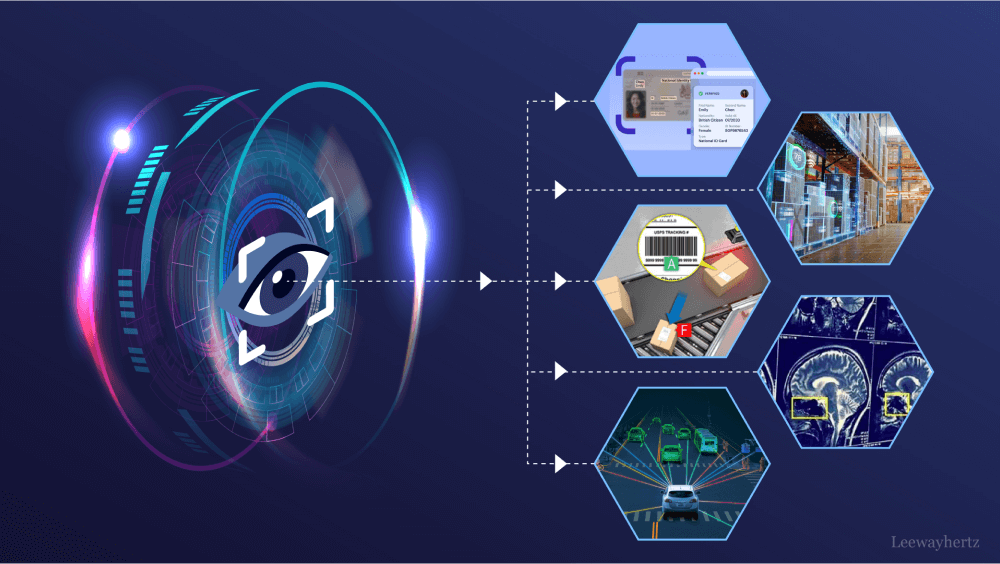
Vision Transformers in Real-World Applications
Transformers on the visual front are being applied in the medical field to process medical images, diagnose and identify diseases with great precision.
Vision Transformers have also been used in self-driving cars in allowing the self-driving software to detect obstacles, lane markings and road signs against the complex environment.
Vision Transformers in Retail and E-commerce
The analysis of images of the products and the user-generated contents makes it possible to apply vision Transformers to more precise visual search of the products, recommendation engines as well as automatic tagging of catalogs.
The virtual try-on systems are also facilitated by the ability of Vision Transformers to enhance a more segmentation and detection of wore fashion items using the human mode
Vision Transformers in Satellite and Aerial Imaging
Vision Transformers are enhancing the observing of the Earth and the translation of geographical information by understanding the pictures of the satellite and using it in deforestation recognition, land usage, and urban designs.
Vision Transformers are also useful because the large educational extent of environmental monitoring is much better than contextual information about large spatial data.
Vision Transformers in Surveillance and Security
Vision Transformers are improving surveillance through visualizing otherwise unknown dubious activity, following action across the cameras and supporting real-time alerts with the help of smart video analytics.
Facial recognition systems are also being enhanced using vision transformers to enhance its performance when working in different lighting conditions and occlusions.
Vision Transformers for Accessibility and Assistive Tech
Vision Transformers enable the development of such AI technologies as the image-to-speech translator or object recognition, which can read out the description of the surroundings.
Quality of text recognition in the natural scenes can be enhanced by Vision Transformers, helping OCR tools to read information on signs, documents, and even written notes.
Multimodal Learning with Vision Transformers
Binarily, Vision Transformer is being co-joined into multi modal AI systems integrating vision and language such as image captioning, visual question answering and scene description.
Vision Transformers are effective when combined with the context-sensitive output enabled by language models through both image and text inputs, at the heart of a system such as CLIP and DALL-E.
Training Vision Transformers Efficiently
To improve performance and lower data needs, Vision Transformers enjoy large-scale pretraining then fine-tuning the performance on skilled downstream tasks.
Training of Vision Transformers could be made more effective employing methods such as knowledge distillation, token pruning and hybrid CNN-Transformer structures.
Leading Vision Transformer Architectures
Vision Transformers are available in different flavors such as ViT (Vision Transformer), Swin Transformer, DeiT (Data-efficient Image Transformer).
Vision Transformers continue to be developed with the active work in creating them faster, more lightweight, and data-efficient enough to run in real-time or on a mobile device.
Open Source and Framework Support for Vision Transformers
Proof of concept PTMs include Vision Transformers, which are implemented in PyTorch, TensorFlow and Hugging Face Transformers and have pre-trained models ready to use.
Libraries ViT Timm The implementation of ViT is available in the research and developers community: timm (PyTorch image models) offers ready-to-train variants of ViT.
Vision Transformers for Edge and Mobile AI
Boosting vision Transformers on edge devices Since their launch, vision Transformers have been optimized with pruning, quantization, and architecture redesign to operate effectively on smartphones and IoT devices.
The applications where the immediate processing of the visual information is required, including AR/VR, robotics, or mobile health monitoring systems, are making Vision Transformers an essential component.
The Future of Vision Transformers
Vision Transformers will remain the key factor influencing the future of computer vision since they have allowed ne AI systems to process and comprehend visual data and environment better.
Transformers in vision may be integrated with generative AI, resulting in systems capable of interpreting, as well as creating realistic and semantically correct images.
Limitations and Ethical Considerations in Vision Transformers
Vision Transformers can be learnt with biases in datasets, and they should be trained and validated responsibly so to enforce fairness in potential applications when applied to hiring or surveillance.
Vision Transformers must be applicable transparently and with interpretability, most notably in such a domain as healthcare, in which the consequences of decisions directly affect human lives.
Vision Transformers in Research and Academia
Hot in AI research are Vision Transformers, where hundreds of papers on new variations, applications and optimizations are published each year.
The research community is examining Vision Transformers in laboratories, research facilities in universities worldwide, defining the future of computer vision innovation.
Choosing the Right Vision Transformer Model
You can choose a Vision Transformer depending on the size of your dataset, how much compute you have available, and your application scenario, either mobile deployment or high-accuracy server inference.
VTs are not universal, and in order to achieve the best architecture, it is essential to compare several of them match your tasks.
Vision Transformers and www.aiviewz.com
Such models as Vision Transformers are presented and described in detail on websites such as www.aiviewz.com where developers and AI enthusiasts may unfold their possibilities.
On www.aiviewz.com, the topics which are discussed, including but not limited to Vision Transformers tutorials, demos, and applications are offered in order to enable the reader to grasp the technology and effectively utilize it where they are required.
Leave a Comment